Normalization Layers are All SAM Needs
Various works have explored the potential connection between flatness of minima and generalization performance of neural networks (e.g. Hochreiter and Schmidhuber, 1997, Keskar et al., 2017, Chaudhari et al., 2017), despite critiques that “sharper minima can generalize better” (Dinh et al., 2017, Andriushchenko et al., 2023). The sharpness-aware minimization (SAM) technique by Foret et al., 2021 actively aims to find minima with low sharpness and was found to be remarkably effective in enhancing generalization performance in various settings (e.g. Bahri et al., 2022, Chen et al., 2022).
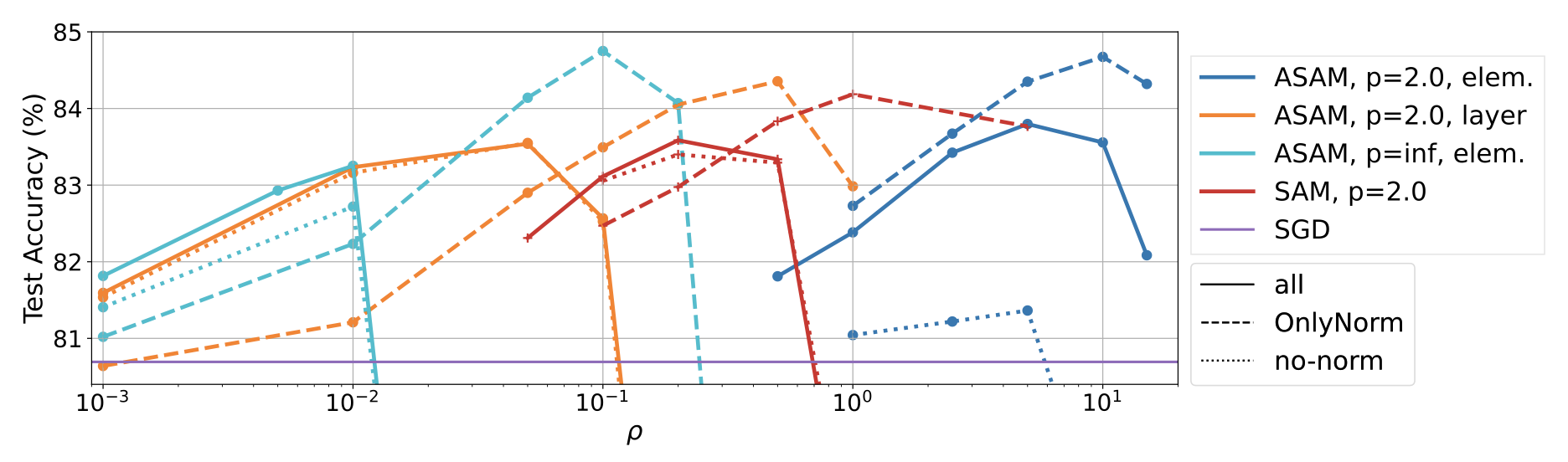
In our work we show that perturbing only the normalization layers (less than 0.1% of the total parameters) outperforms perturbing all parameters (i.e. regular SAM). The figure below illustrates this for a WideResNet-28 on CIFAR-100 data: our approach (SAM-OnlyNorm, dashed line) outperforms regular SAM (SAM-all, solid line) for different SAM variants (where the x-axis is the chosen perturbation radius). Further, we observe that training with SAM-OnlyNorm can in fact increase sharpness, casting doubt on whether SAM’s enhanced generalization performance is caused solely by reduced sharpness.
If this sparked your interest, check out the full paper: arXiv:2306.04226 (which includes a link to the code) and don’t hesitate to get in touch with any questions.
This paper is joint work with Max Müller, David Rolnick, and Matthias Hein and has been accepted to NeurIPS 2023.